
前言
NIS2336编译原理课程的大(?)作业。
代码仓库:

要求如下:
前期准备
了解TINY language语言,并能用TINY language写较简单的程序;
掌握词法分析的步骤方法,能根据程序段模拟自动机的分析过程生成token序列。
TINY language词法分析功能说明
TINY language语言的词法单元:
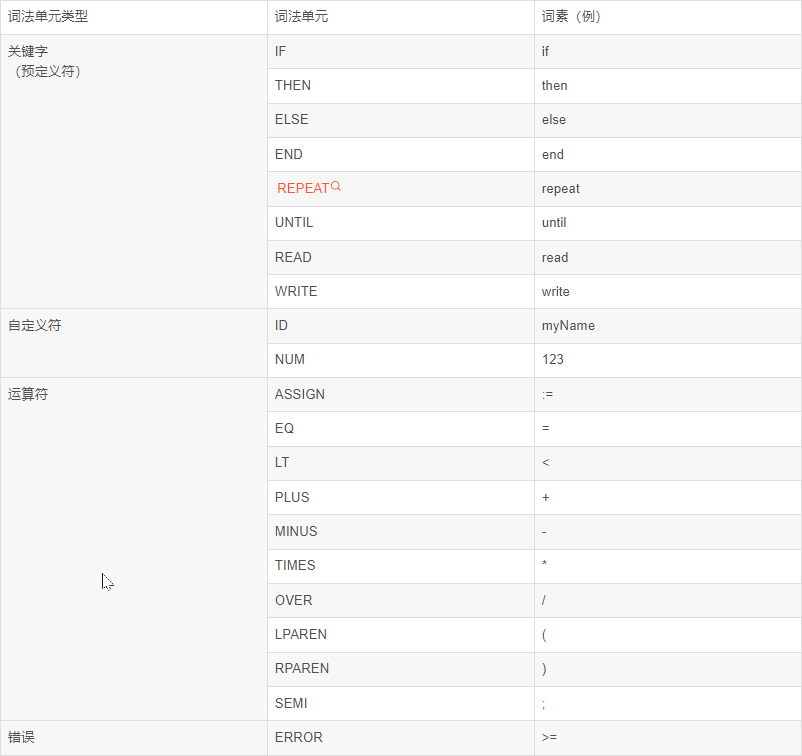 词法单元
词法单元文件global.h中定义了所有的词法单元类型TokenType,并在lexer.h中声明。本次实验要求在读懂lexer.c中已有代码的基础上完善补全lexer.c中的主函数getToken(void),该函数通过判断当前状态并根据当前读入的词法单元来输出当前读入词法单元的token,并更新状态和词法单元,根据给出代码中的示例补全switch语句中case为其他状态时的情况。
处理结果要求
给定一段符合TINY language语法的代码,写成.tny文件,放在build\test文件夹内。要求程序能够输出这段代码的每一行,在每一行的后面输出这一行所有词法单元的token。
示例输入和输出如下所示:
1 | read x |
 example1
example1 example2
example2提交要求和方法
本次实验只对lexer.c进行修改,其他文件不进行修改。在提交时只需将修改完善后的lexer.c上传即可。
DFA
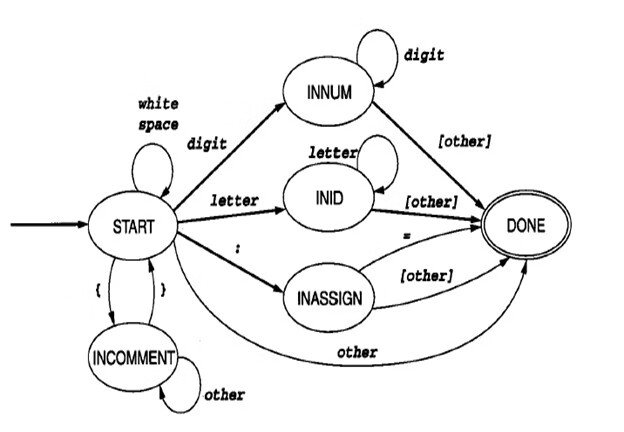 DFA
DFA开始状态为START,终止状态为DONE。
从START状态转移到下一个状态,只需要判定下一个读入的字符即可。
ERROR
从图中可以看到,没有将词法错误ERROR单独作为一个状态来参与状态转移。接下来我们考虑发生ERROR的两种情况:
- 读入的第一个字符不是
{、数字、字母、:以及TINY允许的运算符,则当前字符发生ERROR。 - 读入的第一个字符是
:,但是第二个字符不是=,则上一个字符(:)发生ERROR。
Code
1.
1 | else |
save此时为默认值true,将当前读入的(错误)字符保存以备输出
2.
1 | case INASSIGN: |
若进入INASSIGN后(即读入:后),读入的字符不是=,发生了错误。
调用ungetNextChar()回退一个字符,令该字符参与下一轮的扫描。
save置为false,因为发生错误的是前一个字符:,而不是当前读入的字符。
Lexeme
从示例图的预期输出以及util.c中的printToken()函数可知:
当词法单元类型为Reserved Words, ID, NUM或ERROR时,需要输出其对应的词素。因此在编写程序时,当遇到这几种词法单元,需要将读入的字符逐个保存,以便在到达DONE状态时输出。
Code
1 | /* lexeme of identifier or reserved word */ |
定义了一个名为tokenString的字符数组,用来保存上述情况下的词素。
1 | int tokenStringIndex = 0; |
每一轮扫描会将字符数组的索引置零,以便保存新的词素。
1 | if (state == DONE) |
每一轮扫描结束在字符数组结尾加上终止符\0,因为本轮保存的字符串长度可能小于上一轮保存的字符串长度,这样做可以避免上一轮保存的字符串影响这一轮的输出。
1 | /* flag to indicate save to tokenString */ |
定义了一个整型变量save(实际当作布尔型用),用来指示当前读入的字符是否需要保存到tokenString。
在每一轮循环的开始,即每读入一个新的字符后,save都被置为true,默认要保存该字符。
1 | if ((save) && (tokenStringIndex <= MAXTOKENLEN)) |
每一轮循环的尾部,如果save为true,将当前读入的字符保存到tokenString尾部。
实际上,只有进入INID、INNUM、INASSIGN或读入的字符非预期时,才需要保存读入的一串字符。下面我们逐个情况讨论:
进入
INID1
2else if (isalpha(c))
state = INID;从
START转移到INID时,仅仅转移状态,save仍为默认值true1
2
3
4
5
6
7
8
9case INID:
if (!isalpha(c))
{ /* backup in the input */
ungetNextChar();
save = FALSE;
state = DONE;
currentToken = ID;
}
break;进入
INID后,当且仅当读入非字母时扫描结束。
此时调用ungetNextChar()函数回退一个字符,令该字符参与下一轮的扫描。save置为false表示当前读入的字符不是该轮扫描所得词素的一部分。进入
INNUM实现方法与情况1一致
在前文讨论
ERROR时已给出在前文讨论
ERROR时已给出
Reserved Words
Reserved Words和ID的区别在于:前者由TINY语言预定义,后者由程序员自定义。因此,不严谨地说,Reserved Words也是一种ID。这样,我们可以很自然地将Reserved Words与ID的扫描合并。
具体来说,当读入第一个字符为字母的时候,进入INID状态。在遇到非字母字符时才能转移到DONE状态,在这之前我们都无法确认读入的字符串(即词素)是否是Reserved Words。因此在INID状态期间我们将二者一视同仁,而在转移到DONE状态后对二者进行区分。换句话说,判断读入的词素是否是Reserved Words。
前文说到,当词法单元类型为Reserved Words或ID(亦即进入INID状态)时,我们需要将读入的词素保存。我们在一个包含所有Reserved Words键值对的表进行查找匹配,若保存的词素与表中的词素相同,则返回相应的词法单元,否则表明该词素对应的词法单元为ID。
Code
1 | /* lookup table of reserved words */ |
定义了一个关键字的字典。
1 | if (state == DONE) |
当一轮扫描结束时,如果读入的词素被判定为ID(即该轮扫描经过了INID到DONE的状态转移),则在关键字字典中查找该轮保存的词素。如果查找到,返回相应的词法单元类型;如果未找到,返回ID。
条评论