这是 LLM4Decompile 团队今年(2025年)10月初发布的新工作。
-
论文题目:SK2Decompile: LLM-based Two-Phase Binary Decompilation from Skeleton to Skin
TL;DR #
二阶段反编译,核心思想是将反编译这一复杂任务拆解为结构恢复与语义恢复两个阶段:
- 第一阶段模型专注于重建程序的控制与数据结构,通过设计新的中间语言(IR)将所有变量、函数和类型名统一替换为占位符,从而保证循环、条件、函数调用等结构的完整性。此阶段的强化学习(RL)奖励以结构一致性为核心,鼓励模型生成与原始程序在控制流层面相似的结果。
- 第二阶段则在此基础上恢复语义信息,重点是为标识符、函数调用和数据流重建合理的语义关联。此阶段的 RL 奖励转向语义相似性,引导模型学习更自然、更贴近真实代码逻辑的命名与表达。整体流程中,监督微调(SFT)用于建立基础的结构与语义映射,而分阶段的 RL 则进一步平衡功能正确性与可读性,使最终反编译结果在逻辑上准确且在人类层面具备良好的可理解性。
我的理解是先恢复循环、条件语句、数据结构等,确保结构信息的完整,再恢复语义信息,结构信息完整的情况下其实语义也会恢复得更可读(至少后面一步不会破坏前一步的成果,而且由于冗余的中间变量被消除了很多,模型也能够更专注于恢复有用的变量)。
解决的问题是同时提升功能正确性和语义可读性。核心是将反编译这个复杂任务拆分成两个子任务,毕竟大模型更擅长完成小型任务。
技术路线 #
\({SK}^2Decompile\) 代表 Skeleton to Skin Decompile,将语义结构比作程序的骨架,标识符比作皮肤。

上图展示了\({SK}^2Decompile\) 的框架,其包括两个阶段的反编译过程,即结构恢复和标识符恢复,两个阶段的中间层是文章设计的一种中间语言。两个阶段的模型都使用了 SFT 和 RL,但 RL 的奖励函数不同。
IR #
对于任何信息流 反编译伪代码→ IR →源代码,中间表示必须平衡压缩性和相关性。压缩性意味着 IR 应该从伪代码中丢弃不相关的细节,以使结构恢复阶段易于处理。此外,相关性指的是 IR 必须保留足够的信息以在标识符恢复阶段重构源代码。文章设计的 IR 是混淆后的源代码,即所有标识符都被通用占位符替换,这样所有结构信息被保留、标识符语义信息被删除。
两阶段反编译流程 #
结构恢复挑战,对应 \( P(i \mid u) \) , 在IR 上执行标识符恢复,对应 \( P(s \mid i) \)。
做了一个马尔可夫假设来简化命名概率:
$$ P(s \mid i, u) \approx P(s \mid i) $$
即原始的伪代码相比 IR ,不为标识符重命名提供额外信息。
在此基础上,我们得到最终的概率模型: $$ P(s \mid u) = \sum_i P(s \mid i) \cdot P(i \mid u) $$
于是将从整个反编译优化过程拆成了相对更简单的两步。
RL #
在两个阶段的模型中都用到强化学习(RL),但是它们的奖励函数不同。
其中,结构恢复模型的奖励函数由两部分组成:首先是恢复得到的 IR 能否编译,另一部分是和 ground-truth IR 的相似度系数:
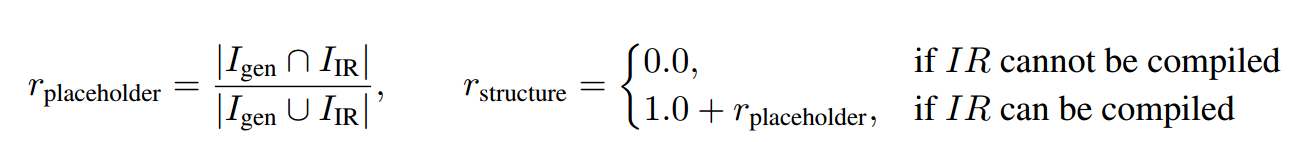
标识符恢复模型的奖励函数为生成代码和参考源代码之间的语义相似度,通过余弦相似度来测量。
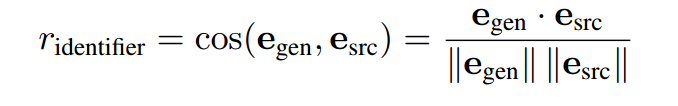
实验 #
为了确保数据质量,做了以下几步:
- 删除所有注释
- 将 clang 格式应用于源代码来规范代码
- 格式化伪代码以遵守 R2I 标准
- 使用 MinHash-LSH 来识别并删除近似重复
指标 #
- R2I 测量代码结构的相对可读性。
- GPT-Judge 使用 GPT-5-mini(OpenAI,2025)来评估输出的标识符有效性,1表示性能差,5表示性能优异。
- 可重新执行率,检查反编译代码是否可以成功重新编译并通过原始测试用例
结果 #
很大幅度地提高了可重新执行率,R2I 和 GPT-Judge 结果也在多数情况下更优,由于是 LLM4Decompile 团队的新工作,所以 \({SK}^2Decompile\) 在各项指标上都要优于前者。
case study #
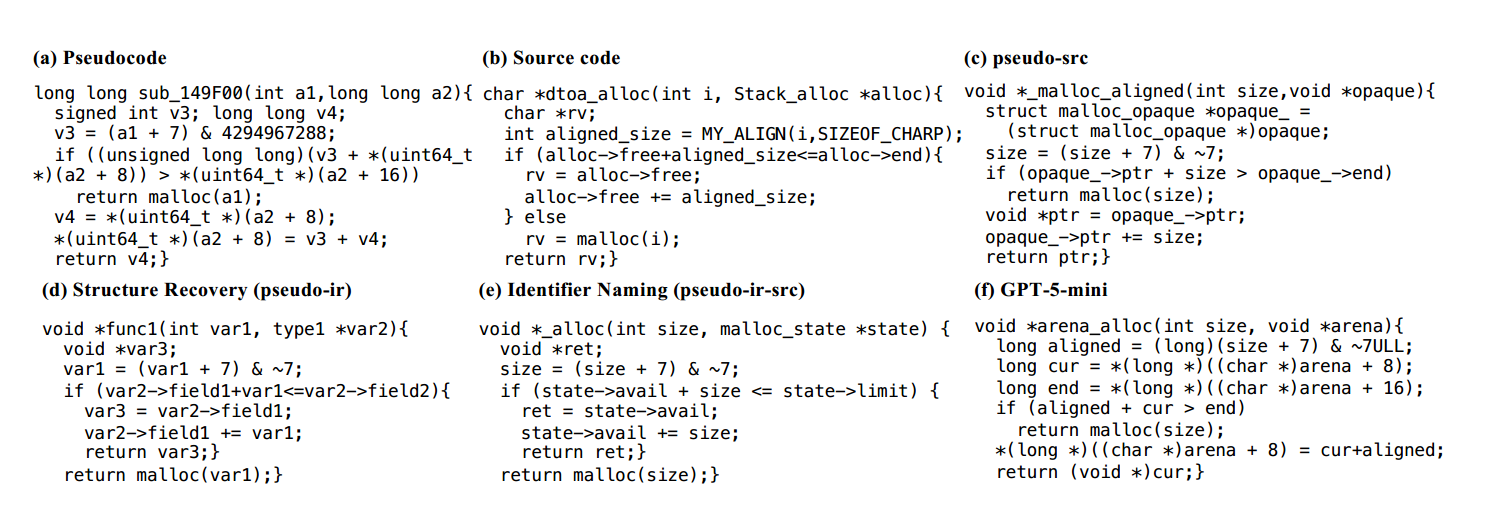
e 的效果确实更好(主要和只有一阶段的c比较)